Dapper 是 Google 的分布式系统追踪基础设施,旨在为 Google 的开发者提供更多关于复杂的分布式系统的行为信息。
简介

如图为一个由 5 个服务器构成的服务:
- 一个前端(A)
- 两个中间件(B 和 C)
- 两个后端(D 和 E)
当用户发起请求到前端服务器 A 之后,会发送两个 RPC 调用到 B 和 C。B 马上会返回结果,但是 C 还需要继续调用后端服务器 D 和 E,然后返回结果给 A,A 再响应最初的请求。对这个请求来说,一个简单的分布式跟踪系统需要记录每台机器上的每次信息发送和接收的信息标识符和时间戳。
设计目标
低消耗(Low Overhead):对接入应用的性能影响应该做到可忽略不计
应用级透明(Application-level Transparency):开发人员对跟踪系统无感知,无需开发人员额外配合改造
可扩展性(Scalability):能够处理可预见未来几年的服务与集群规模
数据及时分析:最好在一分钟内能够将收集到的数据用于分析
解决方案
解决模式
目前学术界与工业界有如下两种方案,将一些记录与某个特定的请求关联到一起:
黑盒模式: 仅记录每台机器上的每次信息发送和接收的信息标识符和时间戳,后使用统计学相关技术去推断关联关系。
简单来说就是不新增日志输出,把现有的日志信息收集后,通过机器学习的模型(比如回归分析)等方式进行关联。
基于标注的模式: 通过侵入性的代码将所有请求的信息标识符和时间戳通过一个全局唯一的id进行关联后进行分析处理。
Dapper使用的是基于标注的模式。
核心原理与流程

术语定义
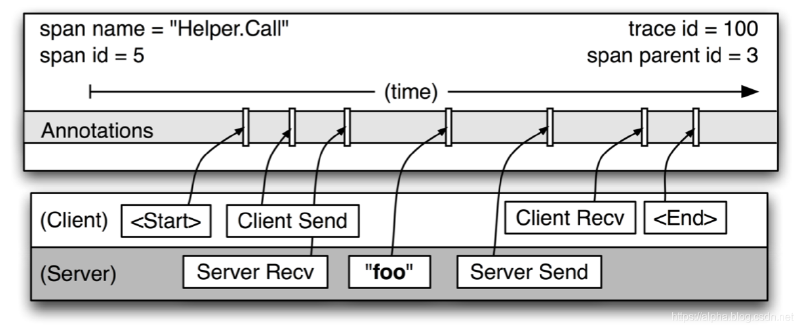
Trace:表示对一次请求的完整调用链的跟踪
Span:两个服务之间的请求/响应过程叫做一次Span,一次Trace中会有多个Span
TraceID:每次Trace过程中产生的全局唯一的ID,在这个Trace的所有Span中都会接收到这个ID
SpanID:通常是多个Span之间的顺序编号
数据结构
Span的结构

主流程
1.当一个线程处理被跟踪的控制路径时,Dapper 会把一个跟踪上下文(trace context)存储到ThreadLocal 中。跟踪上下文是一个小而容易复制的容器,里面包含了 trace id 和 span id 等span属性。
2.当计算过程是延迟调用或异步执行时,多数 Google 开发者会使用一个通用的控制流程库来构造回调函数,并用线程池或其他 executor 来执行回调。Dapper 确保所有的回调都会存储其创建者的跟踪上下文,而当执行回调时这个跟踪上下文会关联到合适的线程上。通过这种方式,Dapper用于重建跟踪的 ID 也能透明地用于异步控制流程。
3.请求结束后,应用将span数据写入本机日志。
4.Dapper守护进程拉取日志文件并将数据读入dapper收集器中。
5.Dapper收集器将结果写入BigTable(开源实现为HBase)中,一次跟踪被记录为一行。

(收集流程)
应用自定义标注
Dapper 也允许应用程序开发者添加额外的信息,以丰富 Dapper 的跟踪数据。
通过显式的API调用,可以将应用的任意内容加入到Dapper的调用链中。比如可以把某个Span的出入参都记录下来。
应用级透明
目前Java业界通常使用Java Agent与字节码增强技术去实现应用级透明的链路追踪,如:Pinpoint
采样率
采样率的大小直接关系到应用的性能损耗,在大流量系统中,通常采用一个较低的采样率(如:0.01%)。
Google 中应用的经验让我们相信,对于高吞吐量服务来说,激进采样并不会妨碍最重要的那些分析。如果一个重要的执行模式在这种系统中出现过一次,那么就会出现上千次。
但在一些流量较低的系统中,即使采样率提高到1%也会漏掉一些重要的事件,这种情况下可以设计一个自适应的采样率,在高流量请求下采样率降低,在低请求量的系统中采样率自动升高。
此外个人认为还可以给一个阈值,如某次Trace的总时间超过一个特定值(如p95),这次Trace就必须被采样。
采样优化
Dapper论文原文中对采样的优化方式为:
对于在收集系统中的每个 span,我们将其 trace id 哈希成一个标量 z (0<=z<=1)。如果 z 小于我们的收集采样系数,我们就保留这个 span 并将它写入 Bigtable;否则就丢弃。在采样决策中通过依靠 trace id,我们要么采样整个 trace,要么抛弃整个 trace,而不会对 trace 中的某些span进行处理。
这里在Dapper收集过程中设置一个二次采样系数,去全局控制数据的最终写入率。
此外我个人认为还可以参考filebeat等log采集器,增加一个过滤管道,针对Trace和span的某些参数进行二次采样。
开销
生成Trace开销
Dapper主要开销在于生成Trace和日志落盘。因此选择一个适当的采样率是十分必要的
收集开销
读本地追踪数据也会干扰被监控的工作负载。
个人推荐使用在容器环境下使用sidecar的形式部署Dapper daemon进程